BOÎTE A OUTILS 1
La première étape de ce projet est l'extraction d'informations de l'arborescence des fils RSS du corpus. Les fils RSS étant des fichiers de la famille XML, répondent de ce fait à une structure précise simplifiant l’extraction de ces informations.
Pour extraire ces informations, on a crée deux programmes distincts :
- Programme Perl : extraction par des expressions régulières
- Programme XML RSS : extraction via la bibliothèque XML::RSS
Le but est de produire deux types de sorties : un fichier TXT et un fichier XML contenant les titres et les descriptions des mises à jours à partir du corpus. Etant donné que les fils RSS appartiennent à différentes rubriques du journal (économie, culture etc.) un fichier de chaque type est produit pour chaque rubrique en utf-8.
La procédure de parcours
Les fichiers sont organisés en répertoires selon la date, l'heure de mise à jour et la rubrique. Pour traiter chaque fichier, le programme doit identifier les éléments de l'arborescence qui sont des répertoires et ceux qui sont des fichiers. Si le programme identifie un répertoire, il parcourt encore l'arborescence en explorant ce répertoire jusqu'à ce que tous les fichiers soient identifiés.
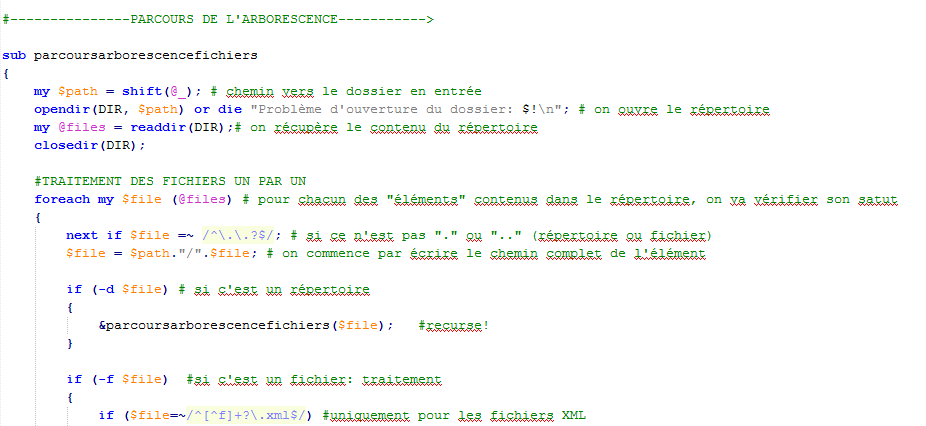
Cliquez pour visualiser le script du parcours de l'arborescence.
![]()
Normaliser l'encodage
Nous savons que le problème le plus récurrent lorsqu'on traite des fichiers textes est l'encodage. C'est pour cela qu'il faudrait s'assurer que les fichiers soient tous écrits dans le même encodage au moment de la lecture et au moment de la sortie. Une manière de proceder pour detecter l'encodage serait de l'extraire directement du fichier.
En explorant les documents RSS, on remarque que la première ligne du document contient une déclaration du type de fichier et de l'encodage.L'encodage sera extrait à l'aide de l'expression régulière suivante:
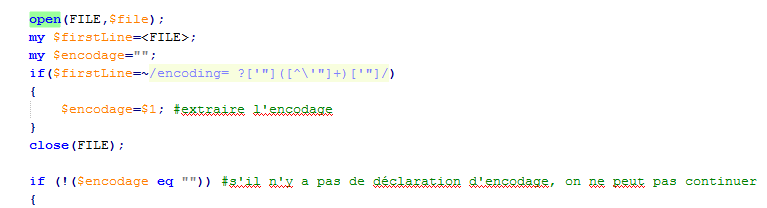
Il est utile de spécifier l'encodage d'origine de chaque fichier lors de son ouverture.

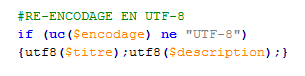
On doit s'assurer que l'encodage soit commun entre les fichiers traités c'est pour cela qu'on va utiliser la bibliothèque XML UnicodeString qui possède une fonction de conversion d'encodage (utf-8) qui fait cette conversion sur la base de l'encodage d'origine fourni.
![]()
Normaliser le formatage
Il existe des fichiers RSS où tout le contenu est sur une seule ligne et des fichiers où chaque balise a sa propre ligne.Il faut donc prévoir une normalisation du format. Le format le plus facile à manipuler pour notre programme Perl est celui où tout le contenu est sur une seule ligne.

![]()
Programme Perl: Extraction d'Information avec des Expressions Régulières
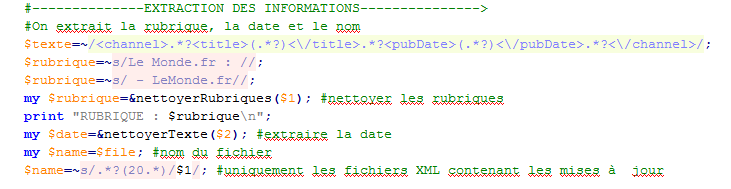
L'extraction des informations peut se faire de deux différentes manières. La première manière consiste à utiliser les expressions régulières. Celles-ci nous permettent de parcourir la structure arborescente des fichiers afin d' extraire certaines zones. Ici on souhaite extraire les parties du texte qui contiennent les balises <title></title> et <description></description>. et pour cela une bouche while parcourt le fichier, repérant les parties du texte correspondant au motif spécifié.

La boucle while parcourt le fichier repérant les parties du texte qui contiennent les balises title et description. Les parenthèses isolent le contenu de chacune de ces balises et le stockent dans les variables $1 (correspondant au titre) et $2 (correspondant à la description).
Ayant extrait le contenue des balises title et description on doit aussi extraire la rubrique parce qu'on doit produire une sortie par rubrique. On peut aussi extraire d'autres informations tels que : la date d'édition et le nom du flux, qui se trouvent à l'intérieur de la balise 'channel'.
![]()
Programme XML RSS:Extraction d'information avec le Module XML::RSS
Le deuxième programme qui extrait les informations tient compte du fait que les fichiers soient des fichiers XML et aient une structure arborescente.Ce programme utilise XML::RSS, un module désigné spécifiquement pour les fichiers RSS. Ce programme effectue les mêmes étapes que le programme Perl, la seul différence entre ces deux programmes est la façon d'extraire les informations.
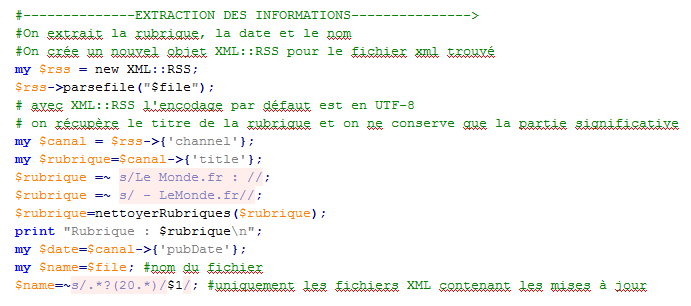
L'objet RSS créé est un tableau associatif qui contient des références vers d'autres références. Une boucle cherche tous les nœuds sous la balise 'items', et pour chaque nœud 'item' extrait le nœud 'title' et 'description'.

Ce programme est plus avantageux parce qu'il n'a pas besoin de normaliser l'encodage et le formatage, c'est le module XML::RSS qui gère ces traitements.
![]()
Nettoyage du Texte
Le nettoyage est un traitement important qui consiste à nettoyer le texte de toutes les entités indésirables par le caractère correspondant. L'extraction de la rubrique se fait à l'intérieur du fichier et est de la forme : 'Le Monde.fr : à la Une' ou bien 'Europe - LeMonde.fr'. Un premier nettoyage est donc nécessaire chez les rubriques.

![]()
Chaque rubrique est convertie en majuscules, tout espace supprimé, toute virgule remplacée par le tiret du huit et tout autre signe de ponctuation enlevé.
Les titres et les descriptions doivent également être nettoyés des entités XML.Pour remplacer les entités XML par les caractères qu'ils représentent, le texte est passé par une fonction qui utilise les expressions régulières pour substituer l'un pour l'autre.
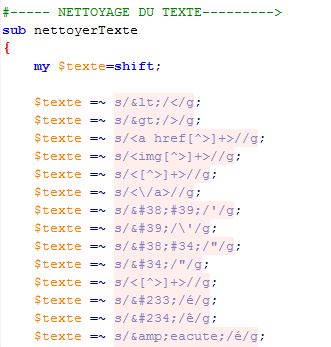
Cliquez ici pour visualiser le parcours Nettoyage du texte
![]()
Non-duplication des informations
En perl les tableaux associatifs permettent d'associer une information unique à une valeur. Cela permettra la non-duplication des informations.
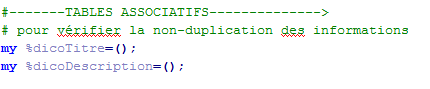
Pour distinguer les informations dupliquées à l'intérieur d'une rubrique des informations dupliquées à travers les rubriques qu'il faut permettre, il faut utiliser un seul tableau pour tous les titres et un autre pour les descriptions et préfixer chaque titre et chaque description de sa rubrique.

![]()
Les Sorties
Sorties TXT
Les sorties en format TXT contiennent une liste des titres et des descriptions. Les sorties TXT par rubrique sont concatenées au fur et à mesure du déroulement du programme.
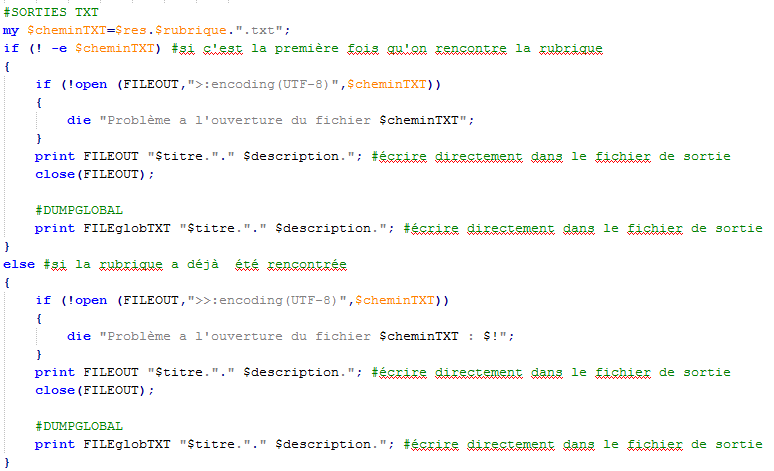
La sortie globale est ouverte avant le lancement de la procédure de parcours, elle concatène au fur les sorties TXT et ferme une fois tous les fils RSS traités.
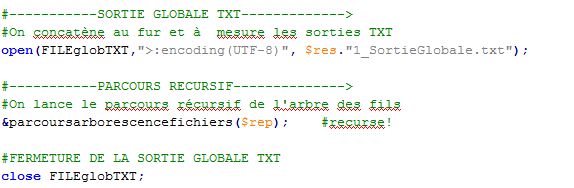
![]()
Sorties XML
Il est important que les sorties en format XML soient bien structurées, avec des balises XML. Les structures des données sont mises en évidence par la présence des balises : une balise 'fichier' (avec son nom et date), à l'intérieur de laquelle est une liste d'items : chaque balise 'item' contient son titre et sa description.
Lorsqu'on rencontre un nouveau fichier, on extrait les informations et on identifie la rubrique. Lors d'un traitement d'un nouveau fichier on écrit une balise ouvrante <file>, qui sera fermée à la fin du traitement du fichier.
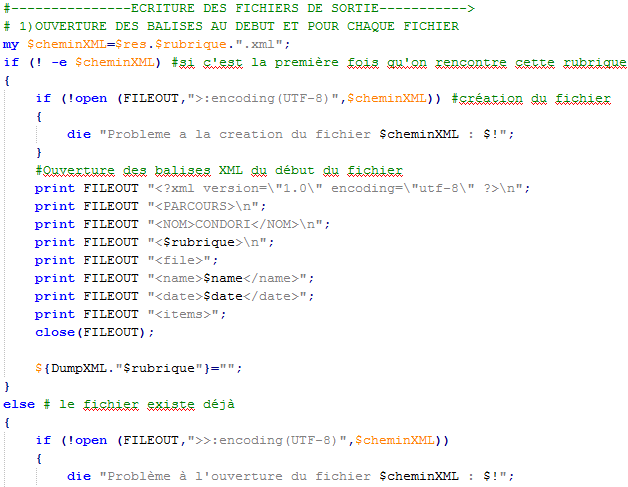

A la fin du traitement on ferme la balise file pour chaque fichier.
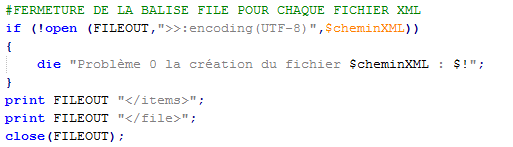
Les items sont ajoutés un par un à l'intérieur de la boucle while. Les titres et descriptions sont écrits sous une balise <item>.

A la fin du programme lorsque toutes les informations sont ajoutées on ferme les balises ouvertes à leur création sauf la sortie globale.
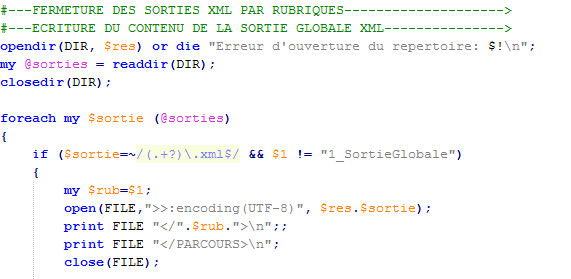
![]()
La sortie globale XML est structurée par rubrique ce qui veut dire que son contenu est écrit à la fin du traitement de tous les fichiers.

La sortie globale peut être construite une fois tous les fichiers traités.
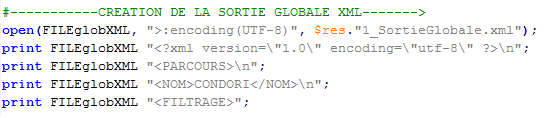
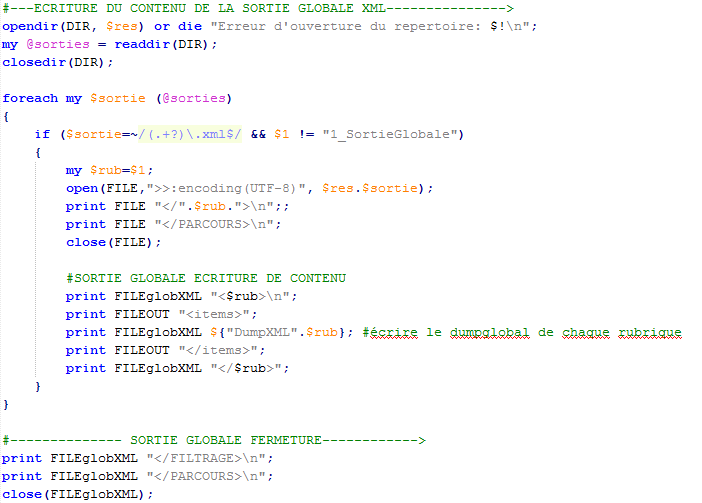
On utilise la boucle pour la fermeture des rubriques afin d' avoir la liste complète des rubriques. A la fin de la boucle on ferme toutes les balises du fichier.
![]()
Voici les exemples de résultats de deux rubriques en format HTML:

Cliquez ici pour visualiser le tableau de la rubrique 'Alaune'

Cliquez ici pour visualiser le tableau de la rubrique 'Economie'
![]()
Téléchargements:
- Programme 'Perl'
- Programme 'XML::RSS'
- Exemple de sortie - 'CULTURE.txt'
- Exemple de sortie - 'ECONOMIE.xml'